

Gaussovka v převleku: proč v CRQ používáme lognormální rozdělení
Představte si, že vám zítra ráno někdo položí jedinou otázku: „Kolik by nás stál úspěšný ransomware útok?“ Pokud odpovíte jedním číslem, pravděpodobně jste právě vyrobili líbivě vypadající omyl. V multiplikativním světě businessu, procent a násobků je totiž „typická“ škoda něco jiného než „průměrná“ škoda. A právě pro komerční sféru dává použití lognormálního rozdělení dobrý smysl.
Jedno číslo nestačí a to je dobře
Incidenty stejné kategorie umí dopadnout řádově odlišně. Jednou to skončí rušným týdnem, podruhé se z toho stane dlouhá a drahá operace s právními, reputačními a provozními sekundárními dopady. Proto se v CRQ neptáme jen na „jednu částku“, ale na celé spektrum možných dopadů a výší ztrát (loss magnitudes) a chceme vidět jejich rozložení, typicky jako histogram empirických dat nebo jako odhadované statistické rozdělení a jeho významné charakteristiky (percentily).
A typické manažerské otázky na standardní percentily přímo cílí:
- Jaká by byla „typická“ škoda (cílí na na medián P50 nebo jinou střední hodnotu)?
- Jak by vypadal „realisticky špatný” případ se špatnou konstelací hvězd (cílíme na P90/P95)?
- Je tam zahrnutý „kolosální průšvih”, kde leží a ohrožuje už existenci firmy nebo důvěru investorů (na P99 a výše)?
Je to podobné jako s počasím: průměrná teplota pro duben vám nenapoví, jestli máte vzít do kufru kabát i tričko. Percentily často napoví více. Jen u možných kybernetických incidentů se místo kabátu a trička řeší cash flow firmy a důvěra zákazníků a investorů.
Představte si dvě firmy, obě zasažené ransomware ten samý týden (protože si Akira vzpomněla i na Čechy). První obnoví provoz za 8 hodin, druhá až za 8 dní. Změnil se útok? Možná ani ne (je to ta samá Akira). Rozhoduje řada detailů: rozsah zasažení, rychlost detekce, připravenost obnovy, rozhodování vedení. A najednou to není „o fous“ větší, ale „o řád”. Kybernetické ztráty žijí v násobcích notoricky známých faktorů.
Multiplikativní svět, kde se ztráty chovají jako násobky
Celkovou ztrátu ovlivní součin řady faktorů: doba výpadku krát náklad za hodinu nedostupnosti systému krát počet zasažených systémů a doba výpadku krát pracnost obnovy krát sazba externích specialistů. A někde v pozadí ještě naskakují eskalační koeficienty typu „kolik procent zákazníků mi to vyeskaluje až do právního sporu“ nebo „kdy už je to na pokutu od regulátora“.
Tyto faktory se nechovají jako malé nezávislé přírůstky, které se nám souhrnně promítnou do známé Gaussovy křivky. Chovají se jako relativní změny (násobky, multiplikátory) typu dvojnásobný čas výpadku krát o polovinu vyšší hodinová ztráta krát třikrát více zasažených systémů – a najednou to není o pár procent výš, ale o celý řád jinde. A obdobné multiplikátory mají v ruce i útočníci, odjakživa se výkupné odvíjelo podle bohatství oběti a u big game hunting ransomware útoků si řeknou o několik procent z ročních tržeb, čili čím větší firma, tím vyšší výkupné.
Všude tam, kde naše škody (nebo pojistné náhrady a roční příjmy firmy) po rozumně dlouhou dobu ovlivňuje mnoho nezávislých relativních (procentuálních) příspěvků, změn a „šoků“, nekopírují data známou „Gaussovku“. Vyjde obrovský rozsah hodnot s viditelnými extrémy, na pravé distribuce vznikne chvost, ocas, dlouhý doběh nebo těžký konec, zkrátka heavy-tail. Elegantní symetrický zvon je zleva výrazně zkrácený a pravostranně šikmý, tj. naprostá většina hodnot je malá, ale několik extrémů napravo všechny převáží a náš středoškolský aritmetický průměr si s daty zjevně neví rady.
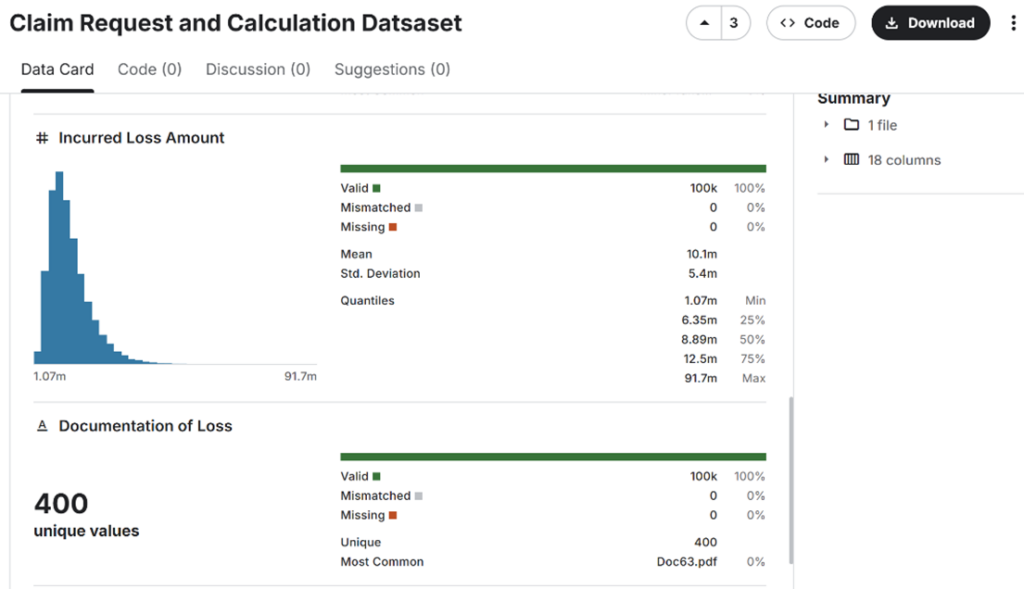
Obrázek 1 – Datová sada 400 ověřených korporátních kybernetických pojistných událostí z portálu Kaggle
Těžký konec aritmetického průměru na pravostranně šikmé ploše není žádnou novinkou přelomu milénia. Už v roce 1879 pánové Francis Galton a Donald McAlister navrhli pro tato data geometrický průměr a práci na logaritmické škále. Na té se pravostranně šikmá data rázem symetrizují do běžné normální distribuce a lognormální distribuce (čti Gaussovka na log škále) je na světě.
Co říkají skutečná data
Ponemon Institute letos publikoval studii The Global Cost of Ransomware Study na základě odpovědí od 2 547 IT a security praktiků ze šesti zemí. CRO, CISO i CRQ riskaři milují Ponemon reporty, mají velké vzorky dat a praktické zaměření na konkrétní hrozbu.
Nás zajímalo, jestli se data z této studie „zachovají normálně“ – tedy jestli ten očekávaný multiplikativní efekt skutečně uvidíme i v reálných reportech.
Vzali jsme histogramy z příloh studie (zaplacené výkupné, počet člověkohodin na obnovu, počet dedikovaných FTE) a nafitovali na ně lognormální distribuce. Výsledek?
Na logaritmické škále se šikmé histogramy promění v symetrické zvony. Objeví se Gaussovka v převleku.
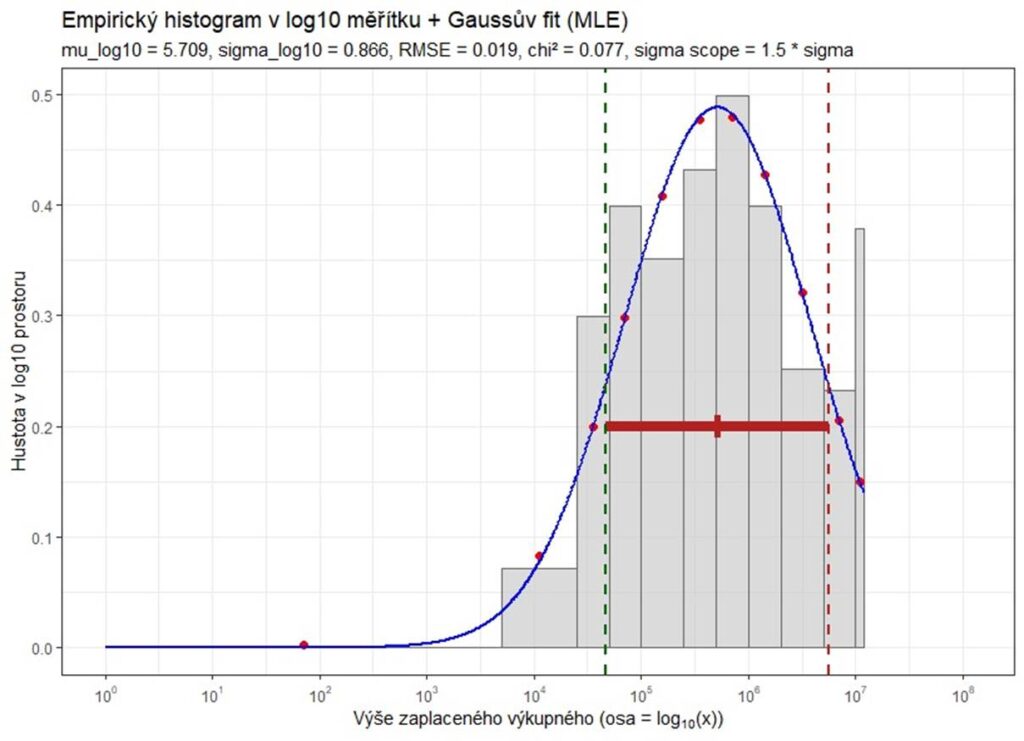
Obrázek 2 – Distribuční křivka výše zaplaceného výkupného na logaritmické škále (zdroj dat: Ponemon Istitute). Střední hodnota lognormálního rozdělení je 105,7 = 500 tis USD, Ponemon uvádí „extrapolated average“ 1 225 tis USD.
Průměry bývají zrádné, ale ten geometrický je střízlivý
Například u požadovaného výkupného vychází střední hodnota (medián) na logaritmické škále okolo 105,7, což odpovídá přibližně 500 tis. USD. Ponemon přitom reportuje „extrapolovaný průměr“ 1 225 018 USD – tedy víc než dvojnásobek. Proč ten rozdíl? Protože pár velkých extrémů umí „stáhnout“ aritmetický průměr výrazně doprava. Medián na logaritmické škále, říkáme mu geometrický průměr, daleko lépe popisuje „typickou“ situaci (očekávanou ztrátu). Aritmetický průměr odpovídá na úplně jinou otázku: „Kolik to průměrně vyjde přes tolik řádově odlišných situací?“
Pokud vám to zní akademicky, vzpomeňte si na „průměrnou mzdu“. Je tak vysoká, že si o ní většina populace může nechat jenom zdát – právě proto, že průměr je tažen menšinou s vysoce nadprůměrným ohodnocením.
A stejný obrázek se ukázal u počtu člověkohodin potřebných na obnovu (geometrický průměr 100 hod vs. Ponemon extrapolovaný průměr 132 hod) i u dedikovaných FTE. Stejný příběh: průměr je tažený těžkým ocasem.
Tři čísla stačí, drahoušku
Vhodnou distribuci bychom už měli a když v CRQ nahradíme jedno číslo lognormální distribucí, získáme současně i nový jazyk, kterým můžeme mluvit s managementem, s riskaři i s boardem:
- P50 (medián): typická ztráta, kdy obnova proběhne plus mínus dle očekávání. Dejme tomu 5 mil. Kč. Situace 50 na 50 (čti „paragánská padina”).
- P90 (realisticky špatné): obnova se zkomplikuje. Třeba 30 mil. Kč. Situace 1 z 10 (čti „nejhorší z posledních 10 nácviků”).
- P99 (ocas distribuce): vysype se, co může. Třeba 130 mil. Kč. Situace 1 ze 100, ale přesně ta, kvůli které existují pojistky a non-IT krizové plány.
Všimněte si těch rozdílů: od P50 k P99 je to v našem příkladě 26-násobek. Ne o 26 % více, ale 26×. Kdo řídí rizika jedním číslem, tento rozdíl prostě nemůže vidět a nerozhoduje o něm.
A to je přesně ten problém, který nás v kvalitativním světě risk matic trápí už roky.
Rychlo-test lognormality a tři otázky pro fanoušky matic
Zkuste si jako rychlý test pro jeden vybraný scénář odhadnou tři čísla – P50, P90 a P99 – a vzájemně je porovnejte. Když jsou v násobcích (a ne v „přičteme pár procent“), máte velmi dobrý důvod začít s modelováním na lognormální křivce.
Pro fanoušky matic máme tři otázky, které by si měl položit každý vedoucí, než zakreslí dopad do heat mapy:
- Jaký je náš P90 a P99 pro daný klíčový scénář (a z čeho rozdílné hodnoty vycházejí)?
- Který faktor nejčastěji posune „typický případ“ do „skutečného průšvihu“ (nezvládnuté RTO, zpožděná detekce, komplikace při rozhodování, nedostupný dodavatel)?
- Co je náš práh bolesti (risk tolerance) v korunách – a jestli a jak často ho v našich úvahách překračujeme?
Proč je to relevantní právě teď
Evropská regulace dává kvantitativnímu přístupu k rizikům stále větší váhu. DORA vyžaduje od finančních institucí systematické a pokročilé řízení ICT rizik (včetně rizik koncentrace) s jasně definovanou tolerancí. NIS2 rozšiřuje okruh organizací, které musí rizika řídit důsledně. „Vyznačte to na matici oranžově“ už přestává být akceptovatelná odpověď na otázku „Jaká je vaše expozice?“
Management i board potřebují jazyk peněz, ne barev. A lognormální distribuce jako naše první volba pro modelování možných ztrát jim tento jazyk nabízí: konkrétní koruny a dolary s percentily a jasnou interpretací, podle které se dá skutečně rozhodovat.
Víc než jen článek
Tento článek je zkrácená a odlehčená verze kapitoly z připravované knihy o kvantitativní analýze kybernetických rizik. V plné verzi jdeme ještě dál: velký bijec Maximus Logaritmus z velkých „násobků“ naseká čtyři malé „přírůstky“ do školky, které pak snadno sečteme, ukážeme si fit lognormálu na reálných histogramech (Ponemon reporty), převedeme výsledky do manažerských metrik a grafů, dáme si pozor na agregaci extrémů v rámci většího portfolia a na závěr si ukážeme i tu obyčejnou diferenciální rovnici pro pravidelné přírůstky, která tiká na pozadí.
Rychlý test pro praxi: zkuste si na jeden scénář zapsat tři čísla – P50, P90 a P99. Když jsou v násobcích (a ne v „přičteme pár procent“), máte velmi slušný důvod začít lognormálem.
Reference a odkazy
• Série článků CRQ na CleverAndSmart: https://www.cleverandsmart.cz/tag/crq/
• Ponemon Institute: The Global Cost of Ransomware Study (January 2025)
• Připravovaná kniha: https://www.cleverandsmart.cz/kvantitativni-analyza-kybernetickych-rizik/


